
AI Engineering
The Thinking Factory: How RAG is Transforming Industrial Decision-Making

In modern factories, machines are already tapped into networks and real-time data across engineering, procurement, and logistics is increasingly consolidated into a single analytics layer across the business. However, there remains a gap — much of the knowledge that actually runs a manufacturing business is still isolated from this system. This is unstructured knowledge that lives in engineering specifications, supplier qualification documents, compliance standards, maintenance manuals, and quality reports.
Without this context, operations data is merely statistics. Managers are left interpreting numbers through the lens of their own experience. With so many variables to track across production, quality, procurement, and compliance (often scattered across dozens of documents), even the most seasoned manager can only make decisions so fast.
This is the problem RAG is built to solve.
Consider what becomes possible when that gap is closed — even at the scale of a small machine shop outside Kitchener, ON:
It's 3 a.m. and no one's on the floor, but a sensor on the CNC mill has flagged an unusual vibration pattern. Fortunately, the system has already reviewed the machine's service history, cross-referenced the OEM maintenance manual, and checked the supplier's last calibration report. Rather than walking into a crisis, the morning team walks into a briefing: a diagnosed probable cause, a draft purchase order for the required parts, and a recommended escalation to the maintenance lead for final sign-off. The system has done the legwork so that the team can act in minutes instead of hours.
So, what is RAG?
If you’ve ever talked to an AI chatbot before, you’ve probably realized that its knowledge can be outdated if not outright hallucinated. This happens because large language models (LLMs) are trained on a fixed snapshot of publicly available data. Retraining them as the world changes is extremely expensive, so their knowledge has a hard cutoff date and no awareness of anything beyond it. More importantly for businesses, this means the models have no knowledge of your operations, machines, suppliers, processes, and standards. Any data outside of an LLM’s training set is external, which may be unstructured or multimodal (e.g., text, image, or video format).
In RAG, external data is first extracted, then converted into a unified, numerical representation (called embeddings) that LLMs can quickly read, and finally stored in a special vector database. This process, known as the data ingestion pipeline, initially builds the knowledge base and then continuously updates it in the background as new data emerges.
Once the foundation is in place, the AI agent can answer your question using RAG:
Retrieval → your query is converted into the same embedded representation and the LLM searches the database for the most mathematically similar embeddings.
Augmentation → the retrieved information is added on to your original query, so that the LLM now has access to this context.
Generation → thanks to this context, the LLM generates a response that is more accurate, specific, and grounded in your own sources.
How is RAG useful in manufacturing?
The utility of a RAG system depends on the knowledge base it can reason over. In an industrial setting, that knowledge base is particularly challenging.
Compared to a corporate FAQ or a customer support database, manufacturing documentation is highly heterogeneous. For example, a single supplier qualification package might contain scanned PDFs, Excel spreadsheets with complex table layouts, and Word documents with embedded diagrams and cross-references. Generic text extraction is not enough as it loses critical structural metadata (e.g., section hierarchies, table relationships, image captions), which are important for traceability and compliance. Moreover, industrial documents evolve over time so the RAG system must not only retrieve the right information but also the right version. Accuracy is critical as an approximate answer, such as a misread torque specification or a missed compliance clause, can cause real consequences in production. Evidently, implementing RAG in production is difficult.
In the 2026 paper “An Industrial-Scale Retrieval-Augmented Generation Framework for Requirements Engineering: Empirical Evaluation with Automotive Manufacturing Data,” researchers evaluated a RAG system on authentic industrial data to measure not just the quality and accuracy but, more importantly, whether the system could actually hold up in a real production environment — factoring in efficiency gains, cost implications, and whether domain experts would trust and accept the outputs in practice.
The paper experiments on documentation from a major German automotive manufacturer: 669 requirements across four specification standards spanning eight years, 49 supplier qualifications, and 127 pages of compliance matrices with format ranging from scanned PDFs with OCR artifacts to native digital structured templates. This corpus embodies the exact data challenges outlined above.
When put to the test over a six-month deployment period with 10,000 queries, the results made a compelling case.
Accuracy
The RAG system achieved a 98.2% extraction accuracy. The 1.8% failure cases were narrow and well-defined: ambiguous requirement boundaries in older legacy documents, requirements that span multiple tables and need to be read together to make sense, and text garbled by imperfect document scanning. These predictable edge cases can be managed by keeping a human reviewer in the loop precisely where the system flags uncertainty, as the paper suggests.
Production Viability Assessment
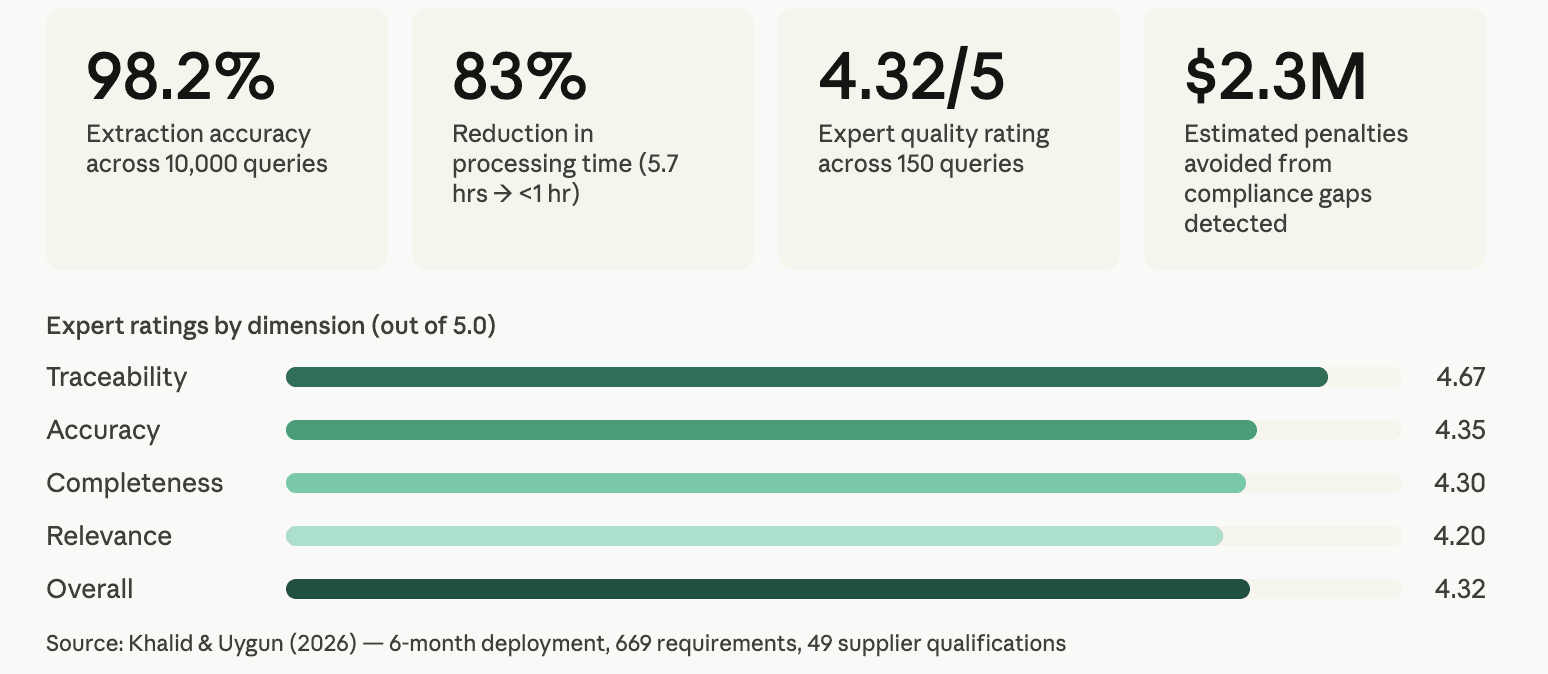
Beyond accuracy, the researchers assessed whether the system could viably replace a manual process in practice.
Domain experts who reviewed the system's outputs across five dimensions rated them 4.32 out of 5.0 overall, with traceability (the ability to follow exactly where an answer came from) scoring highest at 4.67. Especially under compliance obligations, it is crucial for an AI system to provide a clear, auditable trail back to source truths.
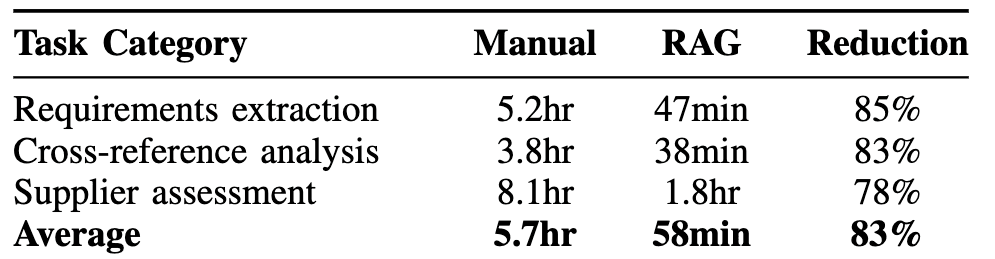
Table 1. Efficiency metrics. Source: Khalid & Uygun (2026).
With regards to efficiency, tasks that previously took an average of 5.7 hours were completed in under an hour; this is an 83% reduction in processing time. For a team managing dozens of supplier qualifications or specification updates simultaneously, this could be the difference between requirements review being a bottleneck and it being a routine task.
Longitudinal Insights
Perhaps the most strategically valuable finding in the study came not from evaluating individual answers, but from what the system revealed when reasoning across eight years of documentation at once.
Over the period studied, the authors found a 55% decrease in the total volume of requirements but a 1,800% increase in IT security-related requirements. This reflects the move towards Industry 4.0, where factories become more connected through more sensors and networks and cybersecurity threats grows as a consequence.
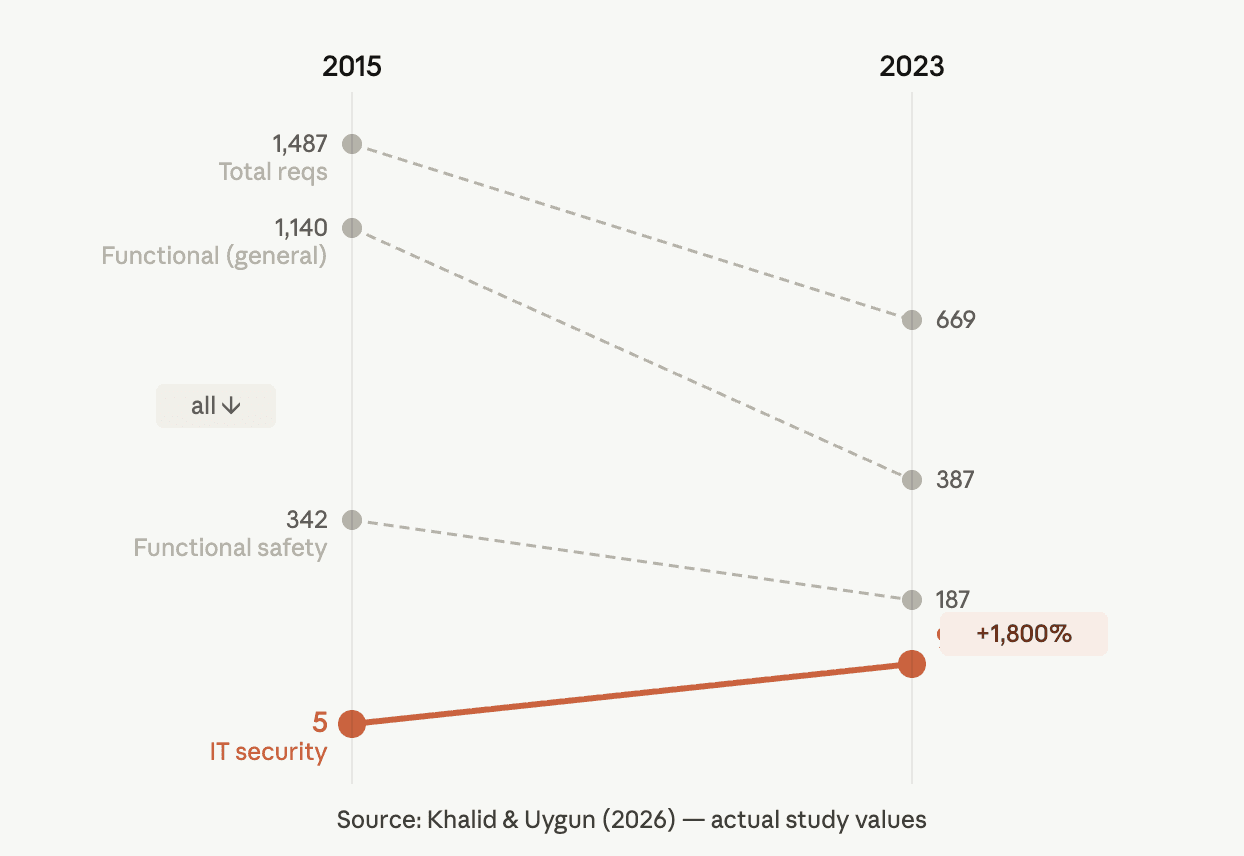
For a team manually reviewing supplier qualifications one document at a time, a shift this gradual would be nearly impossible to spot. By reasoning across eight years of documentation simultaneously, the RAG system identified 10 suppliers — representing over 20% of the supplier base — whose qualifications no longer met current security standards. Left undetected, those gaps carried an estimated $2.3 million in potential contract penalties.
This is one of the key strengths of RAG: surfacing patterns across years of data at a scale and speed no manual process can match. As exemplified in this case study, such a capability shifts compliance from a reactive scramble into a strategic advantage.
Where AdventX comes in ?
The paper’s findings provide evidence for RAG as production-ready technology validated on the kind of messy, heterogeneous documentation that real manufacturing businesses actually deal with. As demonstrated, RAG is more than an efficient search tool. Every manufacturer, regardless of size, is sitting on years of institutional knowledge locked in documents that no system can currently reason over. The question is no longer whether this technology works but whether your business is positioned to take advantage of it.
In fact, according to a recent IBM Institute for Business Value report, 79% of executives say AI will significantly contribute to their revenue by 2030. At the same time, 68% are concerned that their AI initiatives will fail due to lack of integration with core business activities. For smaller manufacturers without dedicated IT teams, that integration gap is even harder to close alone.
This is the problem AdventX is built to solve.
The system described in this article is one component of our broader AI copilot suite designed specifically for small and medium-sized businesses. At its core is an agentic RAG system beyond traditional RAG — with enhanced reasoning, multi-step research, and autonomous action. The result is not just better information, but operational continuity: a vibration anomaly flagged in the middle of the night, its cause traced across service logs and manuals, a draft purchase order ready, and an escalation queued for the maintenance lead — before the first shift even begins.
References
Khalid, M., & Uygun, Y. (2026). An Industrial-Scale Retrieval-Augmented Generation Framework for Requirements Engineering: Empirical Evaluation with Automotive Manufacturing Data. arXiv:2603.20534.
IBM Institute for Business Value. (2026). The Enterprise in 2030. IBM. https://www.ibm.com/thought-leadership/institute-business-value/report/enterprise-2030